
This Front-End Component Might Be Commonly Used in a Few Years
Will AI Replace Front-End Development?
Let's dive into this hotly debated topic both inside and outside the tech community. Most people lean towards the notion that AI doesn't yet have the capacity to completely replace front-end developers—at least not in the short term. This consensus hinges on the fact that AI hasn't reached the level of understanding complex requirements and continuously optimizing code. However, my perspective is a bit more cautionary. I believe that while AI might not directly replace the entire role of front-end developers, it will undoubtedly cause significant disruptions in the job market, leading to a notable reduction in front-end positions.
Think about it: the core task of front-end development is to build user interfaces that facilitate human-computer interaction. With the rapid advancement of AI, this traditional interaction method—through clicks and inputs—might soon become obsolete. Once AI becomes sophisticated enough to allow us to communicate with software using natural language, user operations will become much more straightforward and efficient, with almost no learning curve. For instance, I remember battling with the alignment feature in Word while formatting a document, spending a disproportionate amount of time on layout—a highly inefficient and frustrating task. If AI were smart enough, I could simply command, "Align the first line for me," and it would be done seamlessly. In this scenario, would the complex, densely populated interface of Word need to be simplified or even partially discarded? Does this imply a reduction in front-end roles?
Furthermore, smart speakers like Alexa and Google Assistant are increasingly handling our queries. As robotics technology continues to evolve at a rapid pace, this interaction model is likely to become mainstream, which would also significantly diminish the need for traditional front-end roles.
In a future where most interactions can be resolved through simple conversations, how should front-end pages be designed to remain relevant? I firmly believe that while humans are rational beings, we are also profoundly emotional creatures. No one wants to interact with a cold electronic signal when using software. The user experience would be greatly enhanced if we could engage with a vivid, friendly virtual assistant. Especially if this virtual persona comes with a range of expressions and gestures and can sense and respond to users' emotions and postures, that would elevate the user experience to an entirely new level.
Driven by this intriguing prospect, I decided to develop a simple yet powerful assistant bot component. This bot not only features a 3D model that interacts with users but also allows for customization to fit different scenarios and needs. Its 3D model can even use a camera to capture users' facial expressions, body movements, and more, creating a truly interactive experience.
Getting Started with Development
This section covers the implementation of the assistant robot component. Feel free to follow along with the source code (assistant-robot) and check out the live demo on my personal website.
Creating a 3D Model
Since developers will likely use their custom 3D models with this component, a simple 3D model for development and as a default option is sufficient.
-
Start by modeling the body:
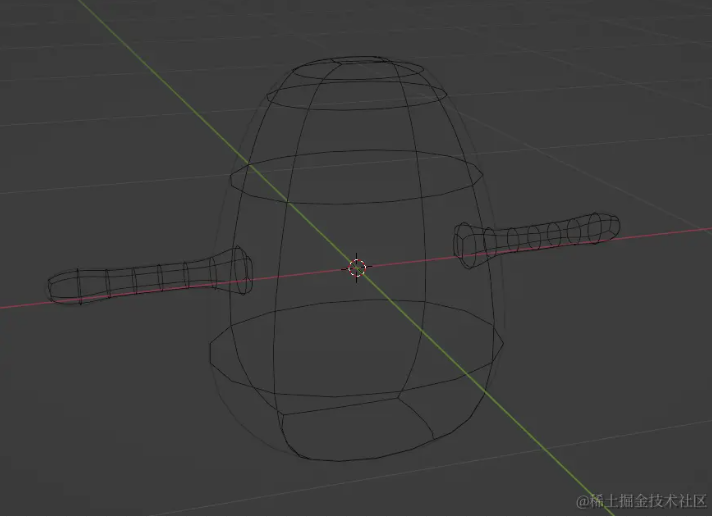
-
Create a texture:
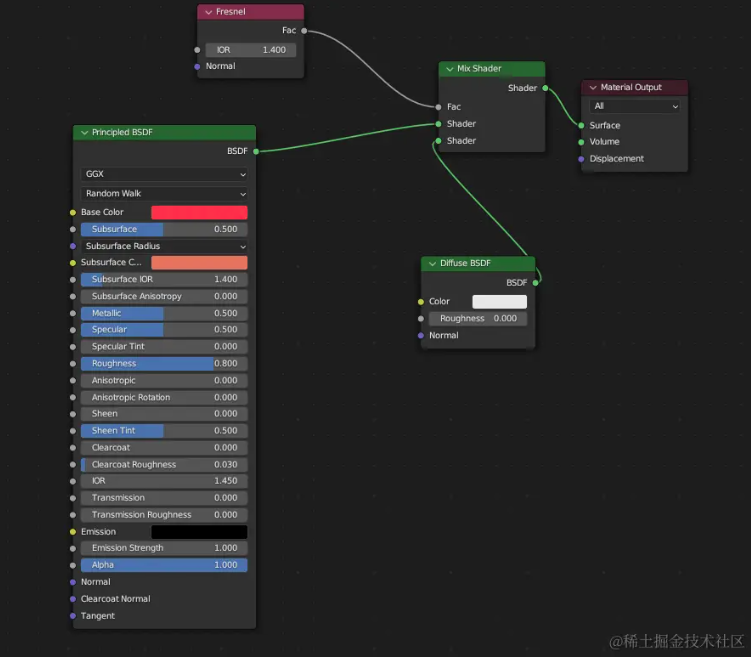
This will result in the following effect:

-
Add eyes and a mouth:

-
Add the skeletal structure:
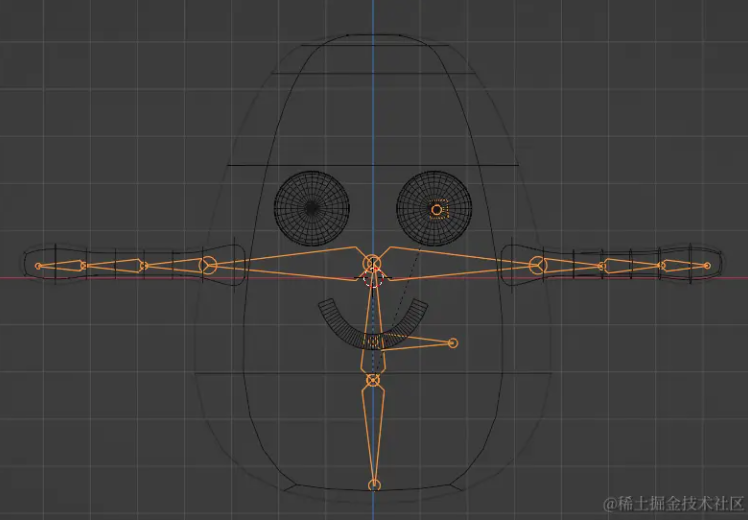
-
Create simple "hello" and "idle" animations:
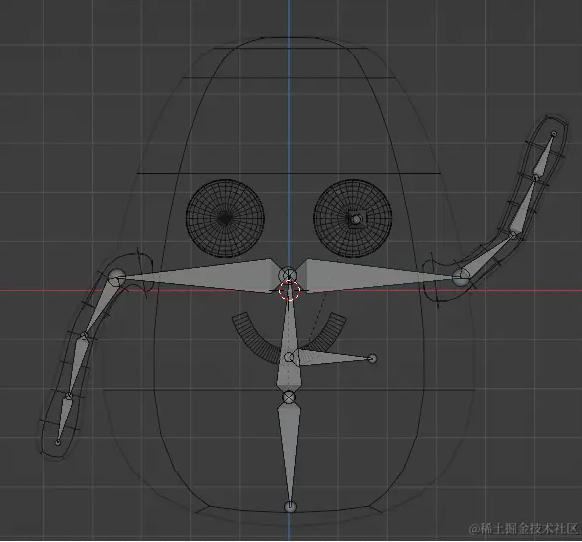
Developing the 3D Assistant and Its Interactions
The AssistantModel class in the assistant-robot library is responsible for the visualization and interaction of a 3D assistant. By leveraging WebGL technology, it creates an interactive robot assistant, making web pages more dynamic and user-friendly. Developers can customize the 3D models and their behaviors, providing users with a unique and engaging interactive experience. Below are the primary features and how each one is implemented:
1. Initializing the 3D Environment and Assistant Model
Feature Description:
The primary task of the AssistantModel class is to create a 3D environment and load the 3D assistant model. It sets up the camera, scene, renderer, and necessary lighting to ensure the assistant model is displayed realistically.
Implementation Details:
-
Camera Initialization: Uses
THREE.PerspectiveCamerato set up the user's perspective. -
Scene Creation:
THREE.Sceneis used to create a scene where the assistant model and light sources are added. -
Rendering:
THREE.WebGLRendererrenders the scene and displays the computed images on a canvas. -
Lighting: Configures lighting, such as
THREE.AmbientLightandTHREE.DirectionalLight, to provide sufficient brightness and shadow effects, enhancing realism.
2. Managing the Assistant Model
Feature Description:
This class loads specific 3D models and makes them the focal point for user interaction. It manages the assistant's animations and expressions to ensure the model appears lively and responsive.
Implementation Details:
-
Model Loading: Uses
THREE.GLTFLoaderto load model files in.glbor.gltfformat. -
Animation Mixing: Utilizes
THREE.AnimationMixerto handle the blending and management of animation clips. -
Timing Control:
THREE.Clockis used to control the timing of animations.
const loader = new GLTFLoader();
loader.load(
modelUrl,
(gltf: any) => {
const model = gltf.scene;
model.position.set(...(position || MODEL_CONFIG.position));
model.rotation.set(...(rotation || MODEL_CONFIG.rotation));
this.model = model;
this.mixer = new AnimationMixer(model);
this.clips = gltf.animations;
this.scene.add(model);
this.startIdleAction();
this.animate();
},
() => {},
(errorMessage: any) => {
console.warn(errorMessage);
}
);
3. Animating Actions and Expressions
Feature Description:
The AssistantModel class has the capability to trigger and control specific actions of the model, such as waving or nodding.
Implementation Details:
-
Action Playback: Achieved through
AnimationActionobjects, which can play, pause, stop, and manipulate animation clips (AnimationClip). -
Action Control: Settings include animation looping (
THREE.LoopOnceorTHREE.LoopRepeat), speed, and repetition count.
/**
* Make the robot play an action
* @param name - Name of the action
* @param config - Configuration of the action
*/
play(
name: string,
{
loop = false,
weight = 1,
timeScale = 1,
repetitions = Infinity,
}: IActionConfig = {}
) {
if (!this.clips || !this.mixer) return;
const clip = AnimationClip.findByName(this.clips, name);
if (!clip) return;
const action = this.mixer.clipAction(clip);
action.enabled = true;
action.setLoop(loop ? LoopRepeat : LoopOnce, repetitions);
action.setEffectiveTimeScale(timeScale);
action.setEffectiveWeight(weight);
const repetTime = loop ? action.repetitions : 1; // Default repeat 1 time
// Halt idle action before playing a new action
this.haltIdleAction(
((action.getClip().duration * repetTime) / action.timeScale) * 1000 // Time to halt
);
action.reset();
action.play();
}
Developing User Face Recognition
The UserDetector class is a critical part of the assistant-robot library, focusing on enhancing user interaction experiences. By harnessing modern face recognition technology, this class facilitates real-time face tracking and expression recognition, allowing the 3D assistant model to interact with users in a highly realistic manner. Whether it’s boosting user engagement, creating immersive experiences, or delivering intelligent responses, the UserDetector significantly increases the virtual assistant's utility and appeal. The current implementation tracks the user's face position, and here’s an overview of its key functionalities and how they are implemented.
Face Position Detection
Feature Description:
Detect the user's face position in real-time to ensure the 3D assistant model’s gaze follows the user's movements.
Implementation Details:
-
Camera Capture: Captures the user’s facial data using a webcam.
-
Face Detection: Utilizes the
@tensorflow-models/face-detectionmodel to identify the user’s facial features and position. -
Data Integration: The detected face position data is fed into the 3D model’s control system, enabling the model to adjust its head orientation and simulate eye contact with the user.
// Create the face detector
async createDetector() {
try {
this.detector = await faceDetection.createDetector(
faceDetection.SupportedModels.MediaPipeFaceDetector,
{
runtime: "mediapipe",
modelType: "short",
maxFaces: 1,
solutionPath: this.options.solutionPath
? this.options.solutionPath
: `https://cdn.jsdelivr.net/npm/@mediapipe/face_detection@${mpFaceDetection.VERSION}`,
}
);
} catch (e) {
console.warn(e);
this.setStatus(EUserDetectorStatus.faceDetectorCreateError);
}
}
// Get faces from the video tag
async getFaces() {
if (!this.video.paused && this.detector) {
return await this.detector.estimateFaces(this.video, {
flipHorizontal: false,
});
} else {
return [];
}
}
This setup ensures that the 3D assistant remains attentive and responsive to the user's movements, thereby enhancing the interactive experience.
Implementing Dialogue Functionality
The LanguageModel class serves as a base class within the assistant-robot library. When using this component, developers need to extend this class and embed their business logic within it to provide the necessary functionalities to the assistant-robot.
To facilitate testing and demonstration, assistant-robot includes a MobileBertModel class, which extends from LanguageModel. This class encapsulates a mobile-optimized version of BERT, offering basic question-and-answer capabilities while maintaining a small model size suitable for browser-based environments. Below is a description of the features and implementation details of the MobileBertModel class.
Implementation Details:
-
The
MobileBertModelclass uses Google's Mobile BERT model, a lightweight variant optimized for mobile devices and restricted computational environments. This model achieves significant speed improvements and reduced memory requirements by minimizing the number of parameters and simplifying the network structure. -
Pre-trained machine learning models are imported into the frontend environment using JavaScript libraries such as TensorFlow.js or ONNX.js.
-
The
MobileBertModelclass provides a constructor that allows developers to specify a model URL, enabling the loading of models hosted either remotely or locally. -
The
MobileBertModelclass implements an abstract method,findAnswers, which accepts a question as a string parameter and returns a Promise. The resolved value of the Promise is the generated answer.
// Load the real language model
async init() {
this.status = ELanguageModelStatus.loading;
try {
const config = this.modelUrl ? { modelUrl: this.modelUrl } : undefined;
this.model = await qna.load(config);
this.loaded();
} catch (error) {
console.warn(error);
this.status = ELanguageModelStatus.error;
}
}
/**
* Ask the model a question
* @param question - The question to ask
* @returns The answer to the question
*/
async findAnswers(question: string) {
if (this.model) {
const answers = await this.model.findAnswers(question, this.passage);
const answer = findHighestScoreItem(answers);
return answer ? answer.text : "";
}
return "";
}
Features and Implementation of the OperationManager Class
In the assistant-robot library, the OperationManager class is designed to manage and execute user interactions with the assistant interface. This class is responsible for rendering the operation interface and handling user inputs and commands. Below is a detailed overview of the OperationManager class's features and how they are implemented.
Rendering the Operation Panel
Feature Description:
Create and display an input box and a button for user interaction, allowing users to communicate with the assistant.
Implementation Details:
-
Constructor Input: The
OperationManagerclass accepts a DOM element as the container for the operation interface. -
HTML Creation: Using a utility function
parseHTML, it creates HTML elements for the button (btnDom) and input box (inputDom), and appends them to the DOM container. -
Customization Options: The class allows for customization of the operation panel's styling through configuration parameters, such as
operationBoxClassName, which lets developers modify the default styles.
Handling Operation Inputs
Feature Description:
Capture and process user input from the operation box upon submission.
Implementation Details:
-
Callback Function: The
onAskattribute is defined as a callback function, triggered when the user inputs text and clicks the operation button. -
Capturing Input: The user input is retrieved from
inputDom.valueand passed as an argument to theonAskfunction, which processes the corresponding query or command.
Managing the Operation Menu
Feature Description:
Dynamically build and manage the operation list, and handle user interactions with the menu items.
Implementation Details:
- Configuration Object: The
operationListattribute in the configuration object contains the metadata and menu item configurations (IOperation). - Menu Creation: A trigger button (
menuBtnDom) for the operation menu is created, and the menu items are initialized throughmenuDom. - Handling Click Events: The
onMenuClickattribute defines a callback function that executes the appropriate action based on thekeyof the clicked menu item.
Features and Implementation of the Assistant Class
The Assistant class serves as the main interface for the assistant-robot library, offering a comprehensive set of APIs that developers can use to create and manage a 3D assistant. Through these functionalities, the assistant can interact with users more naturally, answer questions, and perform a variety of actions.
Feature Overview
The Assistant class provides a suite of methods that allow developers to instantiate and control the assistant robot on a webpage. Key features include initialization, Q&A interactions, text (and eventually voice) output, and action control.
Implementation Details:
-
Instance Creation: When creating an
Assistantinstance, a DOM element is passed in as the container for displaying the assistant robot. -
Customization Options: Developers can customize the assistant's behavior and appearance using configuration objects (
IAssistantRobotConfig). -
Question Handling: The
ask(question: string)method accepts a string parameter as the question to be asked. It returns aPromise<string>, with the promise resolving to the language model's answer. -
Output and Actions: The
assistantSay(text: string)method enables the robot to display text (or potentially vocalize it in the future) and perform corresponding actions. -
Action Playback: The
assistantPlay(name: string, config?: IActionConfig)method allows the robot to perform a specified action. Thenameparameter designates the action, while theconfigparameter provides additional configuration options. This method supports custom 3D models and actions, allowing precise control over which predefined actions or animations the model performs.
/**
* Ask the assistant robot a question
* @param question - The question to ask
*/
ask = async (question: string) => {
this.emit(EAssistantEvent.ask, question);
if (
this.languageModel &&
this.languageModel.status === ELanguageModelStatus.ready
) {
try {
const answer = await this.languageModel.findAnswers(question);
if (answer) {
this.assistantSay(answer);
}
} catch (error) {
console.warn(error);
}
}
};
/**
* Make the robot say something
* @param text - What the robot should say
*/
assistantSay(text: string) {
this.emit(EAssistantEvent.say);
this.assistantModel.say(text);
}
/**
* Make the robot perform an action
* @param name - Name of the action
* @param config - Configuration of the action
*/
assistantPlay(name: string, config?: IActionConfig) {
this.assistantModel.play(name, config);
}
/**
* Make the 3D model of the robot look at the user
*/
async lookAtUser() {
const faceAngle = await this.userDetector.getFaceAngle();
if (faceAngle.length > 1) {
this.assistantModel.rotate(...faceAngle);
}
requestAnimationFrame(() => this.lookAtUser());
}
Conclusion
Currently, the assistant-robot does not yet support voice interaction. Adding speech capabilities is our next key feature, allowing users to communicate with the assistant naturally through spoken language. This will significantly enhance the user interaction experience. Additionally, the assistant will be able to capture and interpret user facial expressions, providing real-time emotional feedback. This enrichment will transform the assistant from a static response system into an intelligent companion capable of perceiving and responding to user emotions.
Once these crucial features are implemented, the assistant-robot will be a comprehensive component for AI-driven user interaction. Developers will find it easy to utilize this tool to handle user interactions, enabling them to focus on implementing their core business logic.
We welcome you to use, contribute to, and star our project. You can find it at: https://github.com/ymrdf/assistant-robot.