
Leveraging AI in Front-End Development: A New Era of Interaction
With the rapid advancement of deep learning technology, the magic of AI is gradually permeating every corner of our daily lives, unleashing infinite possibilities. Particularly in the field of front-end development, AI is like a breath of fresh air, bringing a whole new experience to traditional user interactions. Imagine browsing a webpage through gestures, playing your favorite music with just a smile, or controlling an entire application with a single voice command. These scenarios are no longer scenes from a science fiction movie but will soon become a part of our everyday reality.
Moreover, AI's extraordinary capabilities have become a fountain of inspiration for front-end product innovation. Whether it's text-to-speech (TTS), image classification, or object detection, what once seemed unattainable is now within reach. And as the boundaries of technology continue to expand, high-performance models emerging from communities like Kaggle and Hugging Face are simply breathtaking. For front-end developers to ignore these advancements is undoubtedly a considerable waste of potential.
Additionally, for companies that have already ventured into or plan to introduce AI technology, server costs pose a significant burden. Integrating these capabilities into the front end can drastically reduce costs while enhancing the user experience.
As such, mastering the application of machine learning technology within the browser has become a mandatory skill for front-end developers. In this article, I will guide you through three methods to apply AI in the front end using a series of code examples: by leveraging pre-existing libraries, using TensorFlow.js, and OnnxRuntime-web. These approaches will illuminate your front-end products and make AI your ultimate ally.
Please refer to the accompanying code examples at https://github.com/ymrdf/web-ai-examples for more details.
1 Utilizing Pre-existing Libraries
By using this approach, developers can embed powerful AI capabilities into their applications simply by calling API interfaces. Here are some useful libraries:
-
@tensorflow-models/face-detection: Focuses on facial recognition functionality, capable of identifying faces and key features in images. -
@tensorflow-models/mobilenet: A lightweight model suited for image classification and other visual tasks, optimized for mobile and low-power devices. -
@tensorflow-models/pose-detection: Detects human poses and key points in images or videos, supporting various pose detection algorithms.
As a specific example, we can use the @tensorflow-models/face-detection library to implement facial detection. Below is a simple code example for reference. More detailed implementation and code can be found in this GitHub project:
async createDetector() {
try {
this.detector = await faceDetection.createDetector(
faceDetection.SupportedModels.MediaPipeFaceDetector,
{
runtime: "mediapipe",
modelType: "short",
maxFaces: 1,
solutionPath: this.options.solutionPath
? this.options.solutionPath
: `https://cdn.jsdelivr.net/npm/@mediapipe/face_detection@${mpFaceDetection.VERSION}`,
}
);
return;
} catch (e) {
console.warn(e);
this.setStatus(EUserDetectorStatus.faceDetectorCreateError);
}
}
The advantage of using this method is ease of use. For developers who are not familiar with the principles of deep learning and model training, this approach significantly lowers the technical barrier, allowing for the quick integration of AI capabilities with just a few lines of code. However, there are currently very few ready-to-use libraries available, and it is challenging to find libraries that meet specific needs. Most of the libraries found on npm and GitHub are designed to run on the node side, and their quality is often not high. The three listed libraries above are primarily Google-wrapped pretrained TensorFlow models for the front end, ensuring quality. Other available models can be referenced at https://github.com/tensorflow/tfjs-models/tree/master. Additionally, Transformers.js is also good, but since these models use transformers, they tend to run slowly on the front end: https://www.npmjs.com/package/@xenova/transformers.
2 Using TensorFlow.js to Run Models
TensorFlow.js is a library developed by Google for performing machine learning in the browser or in Node.js. It allows developers to train and deploy machine learning models directly on the client side without relying on server-side computing resources, resulting in efficient data processing and real-time interaction.
Moreover, TensorFlow.js supports the use of existing TensorFlow models by converting them into a web-friendly format. Developers can leverage pre-trained models or create and train new models from scratch, making machine learning more convenient and scalable.
TensorFlow.js supports various model formats, including Keras HDF5, tf.keras SavedModel, and TensorFlow Hub modules from Kaggle.
2.1 Running Pre-trained tf.keras Models with TensorFlow.js
This method supports models saved in formats like Keras HDF5, tf.keras SavedModel, and TensorFlow Hub modules from Kaggle. You can find usable models here: https://keras.io/api/applications/
The main steps are:
-
Save the Model: Save the existing model.
-
Convert the Model: Use the TensorFlow.js converter to convert the model files into a TensorFlow.js-compatible format.
-
Load the Model: Use TensorFlow.js to load and run the model in a web application.
Let's look at how to run a pre-trained model from tf.keras. I have chosen one of my favorite image classification models, InceptionV3:
2.1.1 Save the Model
First, save the pre-trained model in tf.keras as a Keras HDF5 format:
import tensorflow as tf
from tensorflow.keras.layers import Input
input_tensor = Input(shape=(224, 224, 3))
model = tf.keras.applications.InceptionV3(input_tensor=input_tensor, weights='imagenet')
# Save the model as an HDF5 file
model.save('inceptionv3.h5')
2.1.2 Convert the Model
2.1.2.1 Install and Use TensorFlow.js Converter
Reference: https://github.com/tensorflow/tfjs/tree/master/tfjs-converter
Make sure to create a new Python environment and install Python 3.6.8, then execute:
pip install tensorflowjs[wizard]
If you encounter the following error, please upgrade pip:
Could not find a version that satisfies the requirement tensorflow<3,>=2.13.0 (from tensorflowjs[wizard]) (from versions: ...)
No matching distribution found for tensorflow<3,>=2.13.0 (from tensorflowjs[wizard])
If you encounter certificate issues, append --trusted-host parameters:
pip install --trusted-host pypi.python.org --trusted-host files.pythonhosted.org --trusted-host pypi.org tensorflowjs[wizard]
2.1.2.2 Convert the Model
Run tensorflowjs_wizard and follow the prompts to convert the .h5 file into a format supported by TensorFlow.js.
2.1.3 Load the Model
In your front-end project, use the following code to load and use the converted model:
async function loadModel() {
// Use tf.loadLayersModel or tf.loadGraphModel to load the converted model
const model = await tf.loadGraphModel('/inceptionv3/model.json');
const result = model.predict(tf.zeros([1, IMAGE_SIZE, IMAGE_SIZE, 3])) as tf.Tensor;
result.dispose();
return model;
}
2.1.4 Use the Model
Use the following code to make predictions with the model. First, asynchronously load the pre-trained model by calling loadModel() and convert an image at a specified path to a tensor format, imageTensor, for prediction with the model. Then, use the loaded model to predict the image tensor. After obtaining predictions, squeeze the tensor dimensions with tf.squeeze(), apply tf.softmax() to get the probability distribution, and extract the top 5 classes using tf.topk(). Finally, use imagenetClassesTopK() to retrieve the class names corresponding to the indices.
(Reference code: https://github.com/ymrdf/web-ai-examples/blob/main/src/tensorflow/imageRecog.ts)
const model = await loadModel();
const imageTensor = await getImageTfTensorFromPath(path);
const predictions = model.predict(imageTensor) as tf.Tensor;
const squeezed_tensor = tf.squeeze(predictions);
const outputSoftmax = tf.softmax(squeezed_tensor);
const top5 = tf.topk(outputSoftmax, 5);
const top5Indices = top5.indices.dataSync();
const top5Values = top5.values.dataSync();
const results = imagenetClassesTopK(top5Indices, top5Values);
return [results, 0.5];
Below is an example output:

2.2 Running Custom TensorFlow Models with TensorFlow.js
2.2.1 Training a Handwritten Digit Recognition Model
Let's start by training a simple handwritten digit recognition model. Given the straightforward nature of this image recognition task, we can modify a basic convolutional neural network (CNN) model. I've chosen LeNet (https://ieeexplore.ieee.org/document/726791), with a structure close to this:
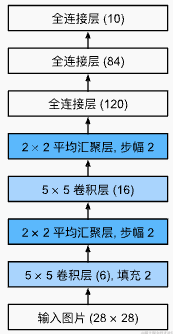
After making several adjustments, including replacing average pooling layers with max pooling layers, changing the activation functions of fully connected layers to ReLU, and adding batch normalization layers after the convolutional and fully connected layers, the final model looks like this:
from tensorflow.keras import layers, models, Input
model = models.Sequential([
Input(shape=(28, 28, 1)), # Specify input shape with Input layer
layers.Conv2D(6, kernel_size=(5, 5), padding="same", activation="sigmoid"),
layers.BatchNormalization(),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(16, kernel_size=(5, 5), activation="sigmoid"),
layers.BatchNormalization(),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(120, activation="relu"),
layers.BatchNormalization(),
layers.Dense(84, activation="relu"),
layers.BatchNormalization(),
layers.Dense(10, activation="softmax")
])
We then train the model with the following code:
import tensorflow as tf
from tensorflow.keras import datasets, models, layers, Input
from tensorflow.keras.utils import to_categorical
# 1. Load the dataset
(training_images, training_labels), (test_images, test_labels) = datasets.mnist.load_data()
# Data preprocessing
training_images = training_images.reshape((60000, 28, 28, 1)).astype("float32") / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype("float32") / 255
# Convert labels to one-hot encoding
training_labels = to_categorical(training_labels)
test_labels = to_categorical(test_labels)
# 2. Define the model
model = models.Sequential([
Input(shape=(28, 28, 1)),
layers.Conv2D(6, kernel_size=(5, 5), padding="same", activation="sigmoid"),
layers.BatchNormalization(),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(16, kernel_size=(5, 5), activation="sigmoid"),
layers.BatchNormalization(),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(120, activation="relu"),
layers.BatchNormalization(),
layers.Dense(84, activation="relu"),
layers.BatchNormalization(),
layers.Dense(10, activation="softmax")
])
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.05),
loss='categorical_crossentropy',
metrics=['accuracy'])
# 3. Train the model
model.fit(training_images, training_labels, epochs=5, batch_size=64, verbose=2)
# 4. Evaluate the model
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print(f"Test accuracy: {test_acc * 100:.2f}%, Test loss: {test_loss:.4f}")
By adjusting the learning rate to 0.05, the model achieves an accuracy of 98% on the test set. To save this model as a Keras file, add the following code:
model.save("./numberRecog.h5")
2.2.2 Converting the Model
Convert the model by following the same process as described earlier. Run tensorflowjs_wizard and follow the prompts to generate the model files.
2.2.3 Loading the Model
Use tf.loadLayersModel or tf.loadGraphModel to load the converted model, depending on the format chosen during the conversion. Here's an example code (reference: https://github.com/ymrdf/web-ai-examples/blob/main/src/tensorflow/numberRecog.ts):
async function loadModel() {
const model = await tf.loadGraphModel('/numberRecogV1/model.json');
const result = model.predict(tf.zeros([1, IMAGE_SIZE, IMAGE_SIZE, 1])) as tf.Tensor;
result.dispose();
return model;
}
2.2.4 Using the Model
export async function inference(path: string) {
const model = await loadModel();
const imageTensor = await getImageTfTensorFromPath(path);
const predictions = model.predict(imageTensor) as tf.Tensor;
const squeezed_tensor = tf.squeeze(predictions);
const outputSoftmax = tf.softmax(squeezed_tensor);
const top5 = tf.topk(outputSoftmax, 5);
const top5Indices = top5.indices.dataSync();
return [top5Indices, 0.5];
}
When using your trained model, the results may vary, and here are some examples:



The methods described above can only load models trained with TensorFlow. They cannot run models trained with other frameworks like PyTorch. However, many resources, such as books and research papers, use PyTorch for demonstration, and pre-trained models available online are predominantly in PyTorch. Is there a way to run models trained with any framework?
(One could transfer the parameters from other models to TensorFlow, then use TensorFlow.js to build and load the model. However, this approach is quite challenging, error-prone, and not easily accessible for most people.)
3 Running Models with ONNX Runtime Web
ONNX (Open Neural Network Exchange) is an open-source deep learning model exchange format developed by Microsoft and Facebook. Its goal is to facilitate interoperability between different deep learning frameworks, allowing models to be seamlessly converted and run across various platforms and tools. ONNX supports various mainstream deep learning frameworks like PyTorch, TensorFlow, and Caffe2, simplifying the model deployment process and improving development efficiency. With ONNX, developers can easily share and reuse deep learning models in different environments, enhancing the flexibility and portability of AI projects.
ONNX Runtime Web is a tool that enables running ONNX models in the browser. It allows deep learning inference right on the front end, without relying on backend servers. By leveraging WebAssembly and WebGL, it achieves efficient performance across different browsers. ONNX Runtime Web is a universal method for running AI models on the client side, and mastering this tool can solve many challenges.
The primary steps for running models on ONNX Runtime Web are:
-
Save the model: Export the existing model to an ONNX file.
-
Load the model: Use onnxruntime-web to load and run the model in a web application.
-
Run the model.
3.1 Running Pre-trained PyTorch Models
3.1.1 Exporting the Model
PyTorch provides several pre-trained models. For demonstration, I chose the ResNet18 model. Other models can be found here: https://pytorch.org/vision/stable/models.html.
Convert the PyTorch model to ONNX format using PyTorch's torch.onnx.export function. The primary process involves loading the pre-trained ResNet18 model:
import torch
from torchvision import models, transforms
from PIL import Image
# Load the pre-trained ResNet18 model and set it to evaluation mode
resnet18 = models.resnet18(pretrained=True).eval()
transform = transforms.Compose([
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
image = Image.open("./1.jpeg")
# Generate input tensor, here using an image to test the model operation
image = transform(image).unsqueeze(0)
with torch.no_grad():
outputs = resnet18(image)
input_names = ["actual_input_1"]
output_names = ["output1"]
# Export the model
torch.onnx.export(resnet18, image, "resnet18.onnx", verbose=False, input_names=input_names, output_names=output_names, opset_version=7)
3.1.2 Loading the Model with ONNX Runtime Web
ONNX Runtime Web's InferenceSession.create() is an asynchronous method used to load an ONNX model file specified by the path in the first parameter.
In the .create() method, a configuration object is passed, which has two fields:
-
executionProviders: ['webgl']: Specifies the backend executor for running the model. Here, it is set to use WebGL to accelerate computations, although CPU or WASM can also be chosen. -
graphOptimizationLevel: 'all': Specifies the level of graph optimization. Setting it to'all'enables all available graph optimizations to enhance model execution efficiency and performance.
(Reference code: https://github.com/ymrdf/web-ai-examples/blob/main/src/onnx/imageRecog.ts)
const session = await ort.InferenceSession.create('/resnet18.onnx', {
executionProviders: ['webgl'],
graphOptimizationLevel: 'all',
});
3.1.3 Running the Model with ONNX Runtime Web
First, create an empty input data object feeds and add the preprocessed data preprocessedData according to the model's input name. Run the model by asynchronously executing session.run(). Then, obtain the model's prediction results from the output data, apply the softmax function to these results to get the probability distribution, and use the tf.topk() method to find the top five predictions and their indices. Finally, use the imagenetClassesTopK function to convert these indices to specific class names and return this information along with the inference time.
const start = new Date();
const feeds: Record<string, ort.Tensor> = {};
feeds[session.inputNames[0]] = preprocessedData;
const outputData = await session.run(feeds);
const end = new Date();
const inferenceTime = (end.getTime() - start.getTime()) / 1000;
const output = outputData[session.outputNames[0]];
const outputSoftmax = tf.softmax(tf.tensor(Array.prototype.slice.call(output.data)));
const top5 = tf.topk(outputSoftmax, 5);
const top5Indices = top5.indices.dataSync();
const top5Values = top5.values.dataSync();
const results = imagenetClassesTopK(top5Indices, top5Values);
return [results, inferenceTime];
Below is the result:

3.2 Finding Pre-trained Models on Platforms like Hugging Face and Kaggle
Although the aforementioned methods are practical, pre-trained models from frameworks like TensorFlow are relatively scarce, and training high-quality models independently can be quite challenging. Thus, the real-world application scenarios might be limited. However, if we can run any model from platforms like Hugging Face and Kaggle, the application scope will greatly expand.
For example, I found a powerful model on Hugging Face: RMBG-1.4. This model excels at accurately segmenting objects in images.
Let's take a look at its impressive performance:

Now, let's implement this functionality in the browser. Excited?
3.2.1 Preparation
First, follow the instructions on RMBG-1.4 to see how to load this model:
from transformers import AutoModelForImageSegmentation
model = AutoModelForImageSegmentation.from_pretrained("briaai/RMBG-1.4", trust_remote_code=True)
Next, write code to test the performance of this model:
from transformers import AutoModelForImageSegmentation
from torchvision.transforms.functional import normalize
import torch.nn.functional as F
import numpy as np
import torch
from skimage import io
from PIL import Image
model = AutoModelForImageSegmentation.from_pretrained("briaai/RMBG-1.4", trust_remote_code=True)
def preprocess_image(im: np.ndarray, model_input_size: list) -> torch.Tensor:
if len(im.shape) < 3:
im = im[:, :, np.newaxis]
im_tensor = torch.tensor(im, dtype=torch.float32).permute(2, 0, 1)
im_tensor = F.interpolate(torch.unsqueeze(im_tensor, 0), size=model_input_size, mode='bilinear')
image = torch.divide(im_tensor, 255.0)
image = normalize(image, [0.5, 0.5, 0.5], [1.0, 1.0, 1.0])
return image
def postprocess_image(result: torch.Tensor, im_size: list) -> np.ndarray:
result = torch.squeeze(F.interpolate(result, size=im_size, mode='bilinear'), 0)
ma = torch.max(result)
mi = torch.min(result)
result = (result - mi) / (ma - mi)
im_array = (result * 255).permute(1, 2, 0).cpu().data.numpy().astype(np.uint8)
im_array = np.squeeze(im_array)
return im_array
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model_input_size = [1024, 1024]
image_path = "./profile.jpg"
orig_im = io.imread(image_path)
orig_im_size = orig_im.shape[0:2]
image = preprocess_image(orig_im, model_input_size).to(device)
model.eval()
result = model(image)
result_image = postprocess_image(result[0][0], orig_im_size)
pil_im = Image.fromarray(result_image)
no_bg_image = Image.new("RGBA", pil_im.size, (0, 0, 0, 0))
orig_image = Image.open(image_path)
no_bg_image.paste(orig_image, mask=pil_im)
no_bg_image.show()
Running the above code should successfully segment the objects in the image.
3.2.2 Exporting the Model to ONNX Format
Add the following lines to the above code to generate an ONNX file (due to the newer operators used, it may not support ONNX version 7; use the latest ONNX version and run it on the CPU:
input_names = ["actual_input_1"]
output_names = ["output1"]
torch.onnx.export(model, image, "rmbg.onnx", verbose=False, input_names=input_names, output_names=output_names)
3.2.3 Loading the Model with ONNX Runtime Web
(Reference code: https://github.com/ymrdf/web-ai-examples/blob/main/src/rmbg/predict.ts. Please extract the public/rmbg.onnx file before running the code.)
const session = await ort.InferenceSession.create('/rmbg.onnx', {
executionProviders: ['cpu'],
graphOptimizationLevel: 'all',
});
3.2.4 Running Inference
async function runInference(session: ort.InferenceSession, preprocessedData: any): Promise<any> {
const feeds: Record<string, ort.Tensor> = {};
feeds[session.inputNames[0]] = preprocessedData;
const outputData = await session.run(feeds);
const output = outputData[session.outputNames[0]];
return output;
}
3.2.5 Data Preprocessing
You might be surprised at how simple the code for model inference is, but the tricky part is data preprocessing. For example, this model requires an input tensor with the shape [1, 3, 1024, 1024]. So, you need to get an image and process it into a tensor of this shape. However, the tensor operations provided by ONNX Runtime Web are limited, so I usually use TensorFlow.js for data processing and then convert the TensorFlow tensor into an ONNX Runtime Web tensor.
Here’s an example illustrating the preprocessing steps:
export async function getImageTfTensorFromPath(path: string): Promise<tf.Tensor> {
return new Promise((resolve) => {
const src = path;
const $image = new Image();
$image.crossOrigin = 'Anonymous';
$image.onload = function() {
// 1. Convert the image element to a tensor
const tensor = tf.browser.fromPixels($image)
.resizeBilinear([1024, 1024]) // 2. Resize the image
.toFloat() // 3. Convert to float
.div(tf.scalar(255.0)) // 4. Normalize
.transpose([2, 0, 1]) // 5. Change shape from [1024, 1024, 3] to [3, 1024, 1024]
.expandDims(); // 6. Add a dimension to become [1, 3, 1024, 1024]
// 7. Standardize the tensor
const mean = tf.tensor([0.5, 0.5, 0.5]);
const std = tf.tensor([1.0, 1.0, 1.0]);
const normalizedTensor = tensor.sub(mean.reshape([1, 3, 1, 1])).div(std.reshape([1, 3, 1, 1]));
normalizedTensor.print();
resolve(normalizedTensor);
};
$image.src = src;
});
}
Finally, convert the TensorFlow tensor to an ONNX Runtime Web tensor (conversion function available in the source code).
3.2.6 Data Post-processing
The model generates data in the shape [1, 1, 1024, 1024], with each value being a float between 0 and 1, representing whether the corresponding pixel should be kept.
Here's how to convert this data into an image:
// Convert the image element to a tensor
const tensor = tf.browser.fromPixels($image).resizeBilinear([1024, 1024]);
// Convert output data to tf.Tensor
const alpha4 = convertOnnxTensorToTfTensor(alphaExpanded);
// Remove a dimension
let alpha3 = tf.squeeze(alpha4, [1]);
// [1, 1024, 1024] => [1024, 1024, 1]
alpha3 = tf.reshape(alpha3, [1024, 1024, 1]);
// Scale by 255
alpha3 = tf.mul(alpha3, 255);
combine(tensor, alpha3);
function combine(imageTensor: tf.Tensor, alphaExpanded: tf.Tensor) {
// Concatenate along the last dimension
const combinedTensor = tf.concat([imageTensor, alphaExpanded], -1);
// Convert tensor to Uint8ClampedArray
combinedTensor.data().then(data => {
const clampedArray = new Uint8ClampedArray(data);
// Create ImageData object
const imageData = new ImageData(clampedArray, 1024, 1024);
// Draw to canvas
const canvas = document.querySelector("#test");
const ctx = canvas.getContext('2d');
ctx?.putImageData(imageData, 0, 0);
});
}
Throw the image below into the system:

Below is the result:

3.3 Running Your Own Trained Model
3.3.1 Training a Handwritten Digit Recognition Model with PyTorch
While we've covered how to use TensorFlow.js to run your own trained models, many books and courses use PyTorch as the teaching framework, especially for front-end developers who often start with PyTorch. So let's go through how to load a model trained with PyTorch into a web environment. We'll train a handwritten digit recognition model using PyTorch, mirroring the previous TensorFlow model.
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
# Load training and test data
training_data = datasets.MNIST(root="data", train=True, download=True, transform=ToTensor())
test_data = datasets.MNIST(root="data", train=False, download=True, transform=ToTensor())
batch_size = 64
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
# Check the data shape
for X, y in test_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
# Set device (using GPU if available)
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
# Define the neural network model
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.BatchNorm2d(6), nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.BatchNorm1d(120), nn.ReLU(),
nn.Linear(120, 84), nn.BatchNorm1d(84), nn.ReLU(),
nn.Linear(84, 10)
)
def forward(self, x):
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
print(model)
# Initialize weights
def init_weights(m):
if isinstance(m, (nn.Linear, nn.Conv2d)):
nn.init.xavier_uniform_(m.weight)
# Loss function and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.05) # Try different learning rates for optimization
# Training function
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
# Test function
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100 * correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
# Training the model
epochs = 5
model.linear_relu_stack.apply(init_weights)
for t in range(epochs):
print(f"Epoch {t + 1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
3.3.2 Exporting the Model to an ONNX File
Once you're satisfied with the model's performance, save the model by running the following code to generate an ONNX file:
input = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
torch.onnx.export(model, input, "numberRecog.onnx", verbose=False, opset_version=7)
3.3.3 Loading and Running the Model
(Reference code: https://github.com/ymrdf/web-ai-examples/blob/main/src/onnx/numberRecog.ts)
export async function inference(path: string): Promise<[Uint8Array, number]> {
const imageTensor = await getImageTfTensorFromPath(path);
const preprocessedData = await convertTfTensorToOnnxTensor(imageTensor);
const session = await ort.InferenceSession.create('/numberRecog.onnx', {
executionProviders: ['cpu'],
graphOptimizationLevel: 'all'
});
const start = new Date();
const feeds: Record<string, ort.Tensor> = {};
feeds[session.inputNames[0]] = preprocessedData;
const outputData = await session.run(feeds);
const end = new Date();
const inferenceTime = (end.getTime() - start.getTime()) / 1000;
const output = outputData[session.outputNames[0]];
const predictions = convertOnnxTensorToTfTensor(output);
const squeezed_tensor = tf.squeeze(predictions);
const outputSoftmax = tf.softmax(squeezed_tensor);
const top5 = tf.topk(outputSoftmax, 5);
const top5Indices = top5.indices.dataSync() as Uint8Array;
return [top5Indices, inferenceTime];
}
The results should be similar to the model trained with TensorFlow:
Limitations of ONNX Runtime Web
While ONNX Runtime Web is useful, it has some limitations. The current version of ONNX Runtime Web using WebGL supports older ONNX versions, and some operators may not be supported. Using WebAssembly can support all operators, but it may be slower. Also, large ONNX files can slow down the front-end loading process.
Summary
In this article, we delve into how to run machine learning models in front-end development, focusing on two major methods: TensorFlow.js and OnnxRuntime-web. Initially, we need to save or convert the model into the appropriate format and then use the corresponding tools to load and execute it.
TensorFlow.js allows models created with the TensorFlow framework to run directly in the browser, offering developers a convenient method for model training and deployment. However, the existing resources for TensorFlow.js are relatively limited, and its conversion tool, tensorflowjs_wizard, can be somewhat challenging to use.
On the other hand, OnnxRuntime-web supports loading ONNX models trained with various frameworks, providing greater flexibility. Yet, due to limitations with WebGL, some operators may not be supported, necessitating the use of Assembly to ensure model compatibility, though this comes at the expense of execution speed.
Regarding data processing, the tensor computation methods in OnnxRuntime-web are relatively fewer. We can employ methods from @tensorflow/tfjs for data processing, and then convert the processed results into tensor objects supported by OnnxRuntime-web for further application.
By learning and mastering these techniques, we can seamlessly integrate AI technologies into front-end development, elevating the user experience of web applications to a new level. Whether you are a front-end developer or an AI enthusiast, continuing to explore and learn about AI-related technologies is undoubtedly the key to unlocking the door to future advancements. Let's embrace AI technologies together, boldly explore unknown frontiers, and build smarter and more user-friendly applications!
I hope this article provides you with valuable insights, and may we grow together on the path of merging front-end development with AI technology to create more possibilities!